MARB — Mechanical Assembly Readiness Benchmark
Can AI assemble a real machine? AI can assemble machines in CAD. MARB is the missing yardstick for whether the result is correct and buildable: a tool-independent, automated benchmark graded by CADCLAW and mapped onto the readiness scales industry already trusts: TRL, MRL, IRL.
Benchmark, grades, and write-ups are open (papers & data). White paper review copies: [email protected]

The gap
AI-CAD benchmarking is an active field, there are strong public benchmarks for generating geometry (ABC, DeepCAD, Fusion 360 Gallery, CADBench, Text2CAD-Bench), classifying parts (MCB), and predicting how two parts join (JoinABLe, AutoMate). None grade the capability to a functional mechanical assembly.
No public benchmark asks whether a complete, multi-part machine an AI assembled is correct and buildable: right parts, no collisions, nothing floating, every interface aligned across the whole system, judged automatically, independent of the authoring tool, and tied to a readiness level. That is the niche MARB fills.
The ladder
The benchmark is a ladder. Each rung is defined by the next thing an automated verifier must be able to prove, you can only benchmark what you can verify.
L0 · Component
One part is exactly as specified.
L1 · Assemble the kit Today
Parts placed, aligned, no collisions, nothing floating. The Model T.
L2 · Constraint-robust
Re-solves correctly when parameters change.
L3 · Mechanically valid
Full-travel kinematics + load-holding, measured.
L4 · Engineering change
Re-design to a new requirement, no regressions.
L5 · Design from intent
Pick & arrange parts from functional goals. Tesla.
L6 · Optimize & invent
Provably beat the human baseline, multi-physics.
L7 · Autonomous loop
Design → build → measure → certify → self-improve.
Today the bar is L1. L6–L7 are not achievable by anyone yet, that gap is the measure of the road.
Capability × Readiness
The most useful artifact MARB offers: every rung mapped onto TRL (Technology Readiness), MRL (Manufacturing Readiness), and the integration-focused IRL: so anyone who already speaks readiness-levels can place an AI result instantly.
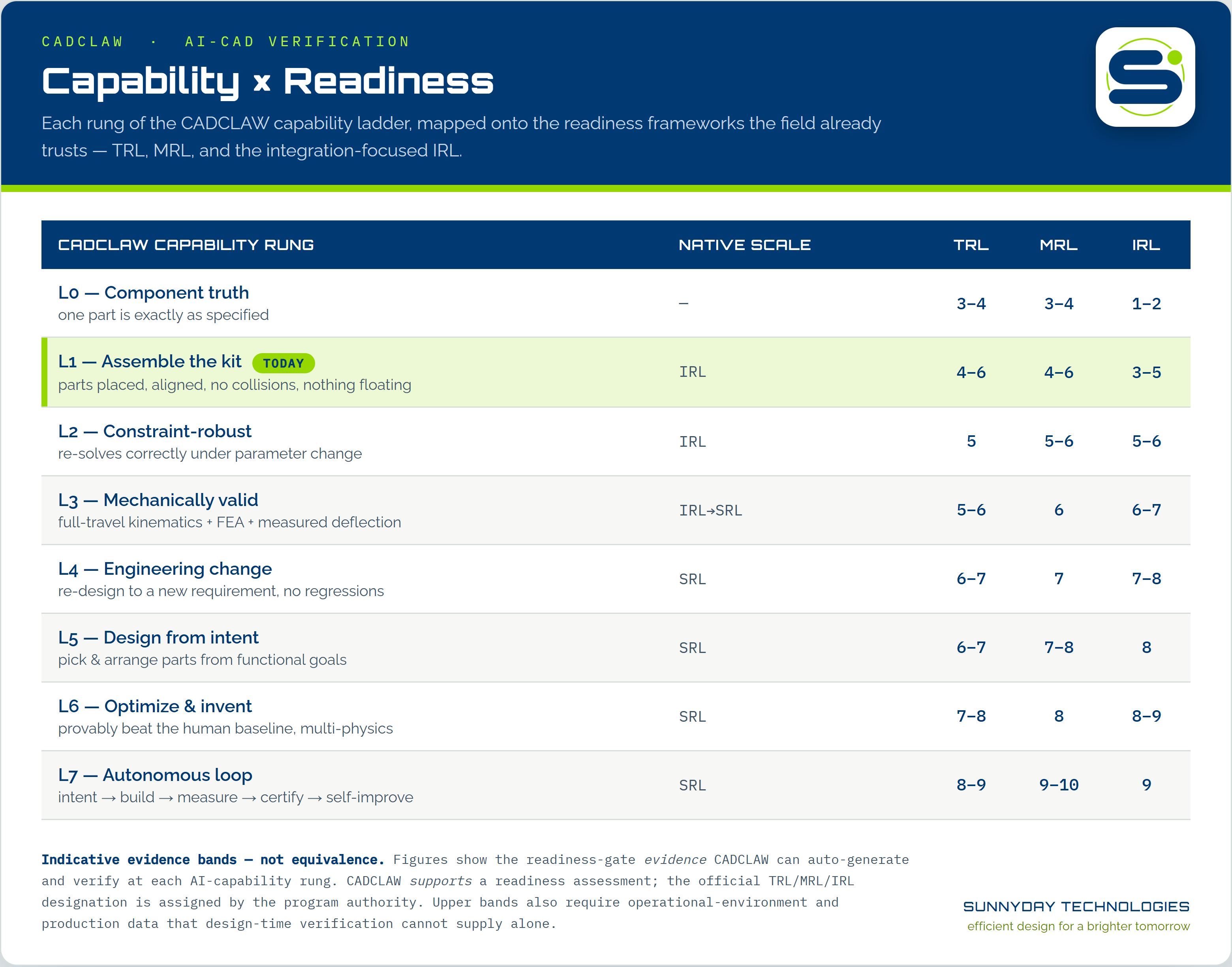
CADCLAW capability ladder ↔ TRL / MRL / IRL, indicative evidence bands, not equivalence.
Two axes, one bridge. TRL/MRL/IRL measure a machine's readiness, assigned by an authority. The ladder measures the AI's capability. CADCLAW is the bridge: it auto-generates the integration evidence those gates consume. The tightest native fit is IRL: CADCLAW's checks (interference, alignment, floating) are integration-readiness evidence.
How the benchmark runs
One task, any tool, one grader. Every AI workflow gets the same prompt + kit and is judged on its exported STEP by the same automated, tool-independent gates, the score is the only thing that differs.

The MARB pipeline, inputs → AI driver → exported STEP → CADCLAW gates → MARB score + readiness → human review, with a read-fix-rerun loop.
The metrics
Every run yields the same small, defined set of numbers, two kinds, never mixed: artifact quality (is the build correct?) and effort (what did it cost?).
Gates
Black-box, on the exported STEP: Inventory (right parts) · Interference (no overlaps) · Floating (all connected) · Orientation (correct pose, v-next).
L1 sub-grade · 0–100
How well the kit is assembled, × a buildability factor that falls with interference (clip count + overlap volume). A self-intersecting frame can't be built, so it can't score high.
MARB full-stack · 0–100
Rung on the L0–L7 capability ladder. A clean L1 ≈ 15 today; the rest of the scale is the road to autonomous design. Mapped to TRL / MRL / IRL.
Effort (reported separately)
Wall-clock, tokens, attempts, retries, corrections, human interventions, measured from the run log, never folded into the score.
Today, L1, on a real machine
The reference is a clean L1: a resolver-built answer key for a two-metre 3D-printer / CNC frame of roughly 100 parts. It is the grading ceiling every AI run is measured against.
- The answer key passes every black-box gate — inventory, interference, floating — with zero findings. That is the grading ceiling, not an AI result.
- Independently graded: the same automated checker that grades every tool, with no human in the loop.
- Best AI run so far: roughly 100 parts placed at 0.0 mm median gap error (Claude · CadQuery), but not buildable yet — structural interference at the frame joints.
The board, 2026-06-11
Eleven graded builds of the same 100-part machine, frontier hosted models down to a local open-weight anchor, ranked by GAP median on one ladder. The board updates as runs land; every cell's provenance (model, tool, timing, tokens, attempts) is in the open run registry. The same board is mirrored as a live Hugging Face Space.
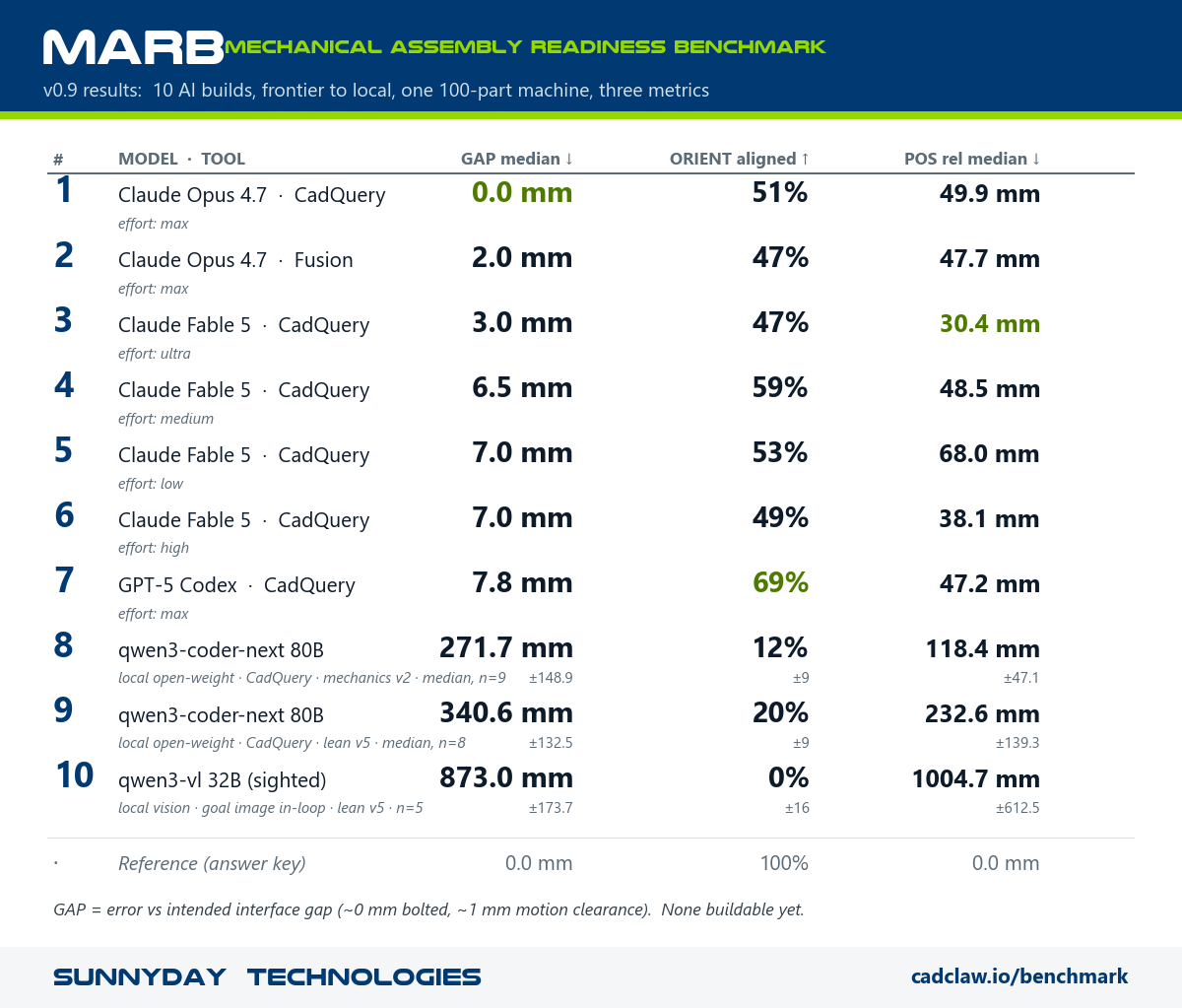
The full board. Claude Fable 5's multi-agent ultra run holds rank 3 and the board-best relative position; Claude Opus 4.8 enters at rank 4 on the hint-equipped v1.3 kit; the local 80B rows carry n=9 and n=8 error bars.
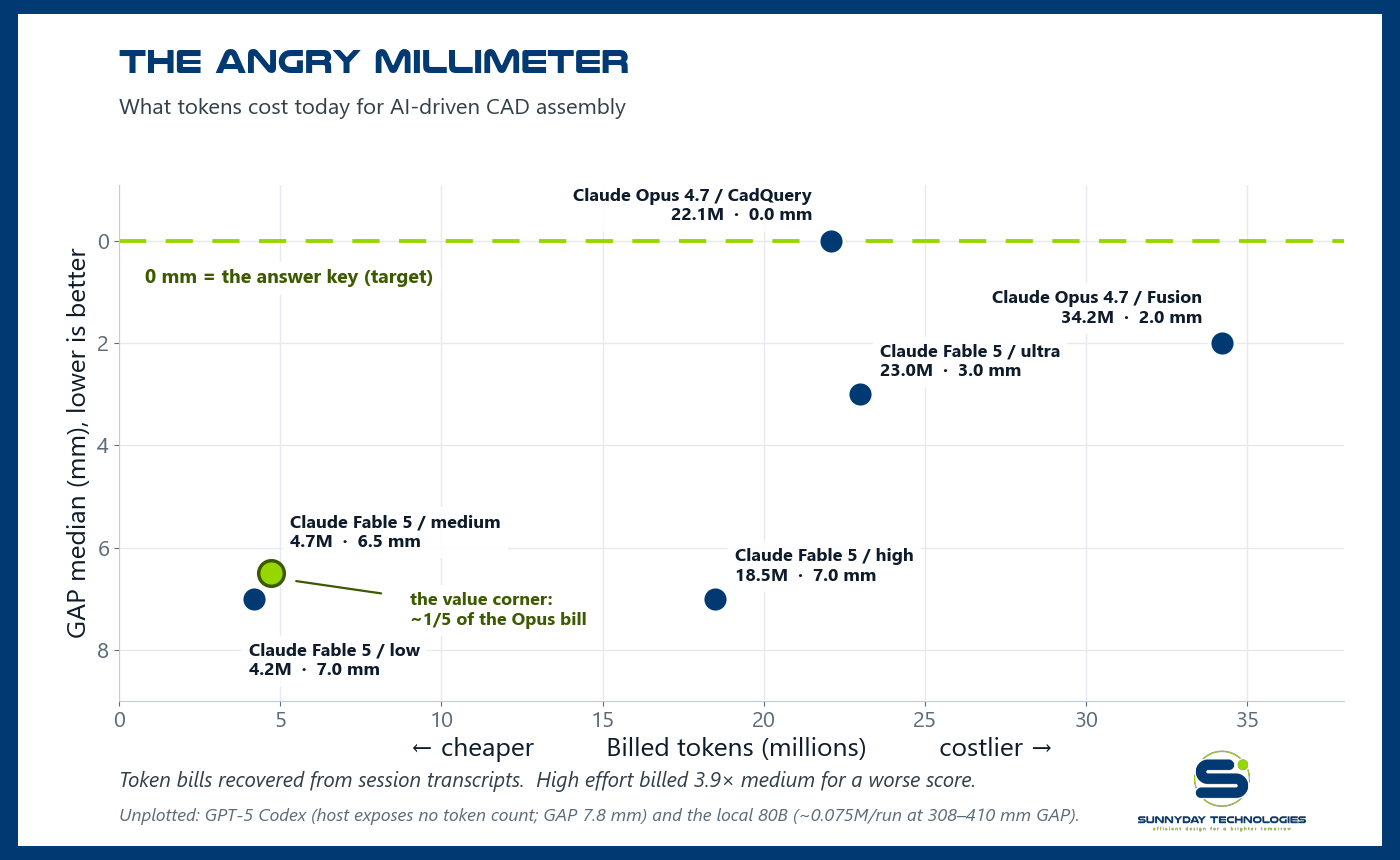
The Angry Millimeter: what tokens cost today. Bills recovered from session transcripts; full ledger and method in the recap.
Deep dives: the recap article (findings to date + the token ledger), the studies log (the Fable 5 effort sweep and the graded local open-weight anchor), and the first-results write-up (the original three-way head-to-head, preserved below as the founding study), and the new MARB-A architecture lane (three models build a house in Pascal; two fall into the same units trap).
First head-to-head (the founding study, 2026-05-26)
Three independent AI workflows, Claude Opus 4.7 (Fusion and CadQuery) and OpenAI Codex / GPT-5 (CadQuery, the coding agent, not the chat app), fresh prompt-only sessions, same kit, graded on the identical black-box lens. All three placed every part with zero human help; none is buildable yet.

One of four goal renders provided (the 3/4 overview); the kit also includes front, top, and side views.
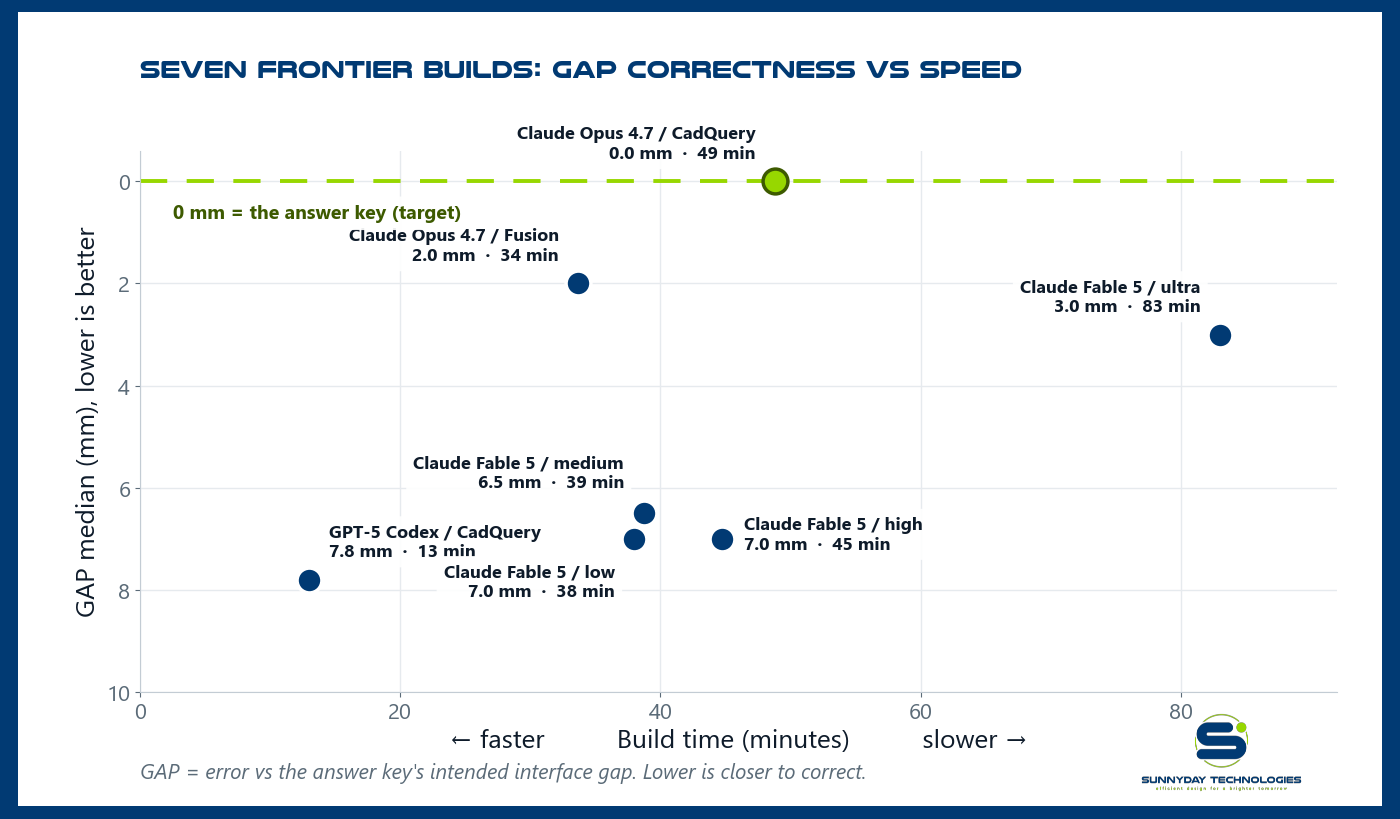
Gap correctness vs. speed, now across all seven frontier builds. OpenAI Codex one-shotted in 13 minutes; the Fable 5 effort sweep clusters mid-board; the ultra run trades 83 minutes for rank 3.
| # | Model · tool | GAP median ↓ | ORIENT aligned ↑ | POS rel median ↓ | Time | Cost est. |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.7 · CadQuery | 0.0 mm | 51% | 49.9 mm | 48.8 min | ~$68 |
| 2 | Claude Opus 4.7 · Fusion | 2.0 mm | 47% | 47.7 mm | 33.7 min | ~$174 |
| 3 | GPT‑5 Codex · CadQuery | 7.8 mm | 69% | 47.2 mm | 13.0 min | not reported |
| n/a | CADCLAW reference (answer key) | 0.0 mm | 100% | 0.0 mm | resolver | n/a |
MARB v0.9. GAP median = error vs the answer key's intended interface gap (≈0 mm bolted, ≈1 mm motion clearance). ORIENT aligned = % of asymmetric parts in the correct rotation. POS rel median = position error relative to each part's neighbours (frame‑invariant). Tolerances are tight by design (≤5 mm = located, ≤5° = aligned); none buildable yet. Cost est. at Anthropic Opus list price (~$15 / $75 per M tokens, $1.50 cache‑read); Codex CLI didn't report tokens. Results 2026‑05‑26 · CadQuery 2.7.0, Autodesk Fusion 2702.1.58 · graded per the MARB v0.9 scoring spec.
Every flagged clip is structural, beams overlapping at splice joints and post/frame junctions, and the centered 2040 inserts overlapping their beams. Both also placed the Z-posts in the wrong rotation versus the reference, an orientation error the current gates don't yet catch, and the next gate we're adding.

Claude-Fusion, building the frame (10 → 100 parts). The model emits no parametric timeline, so we recovered the build order afterward by driving the live Fusion model through its MCP, revealing the placed parts in order under a fixed isometric camera.
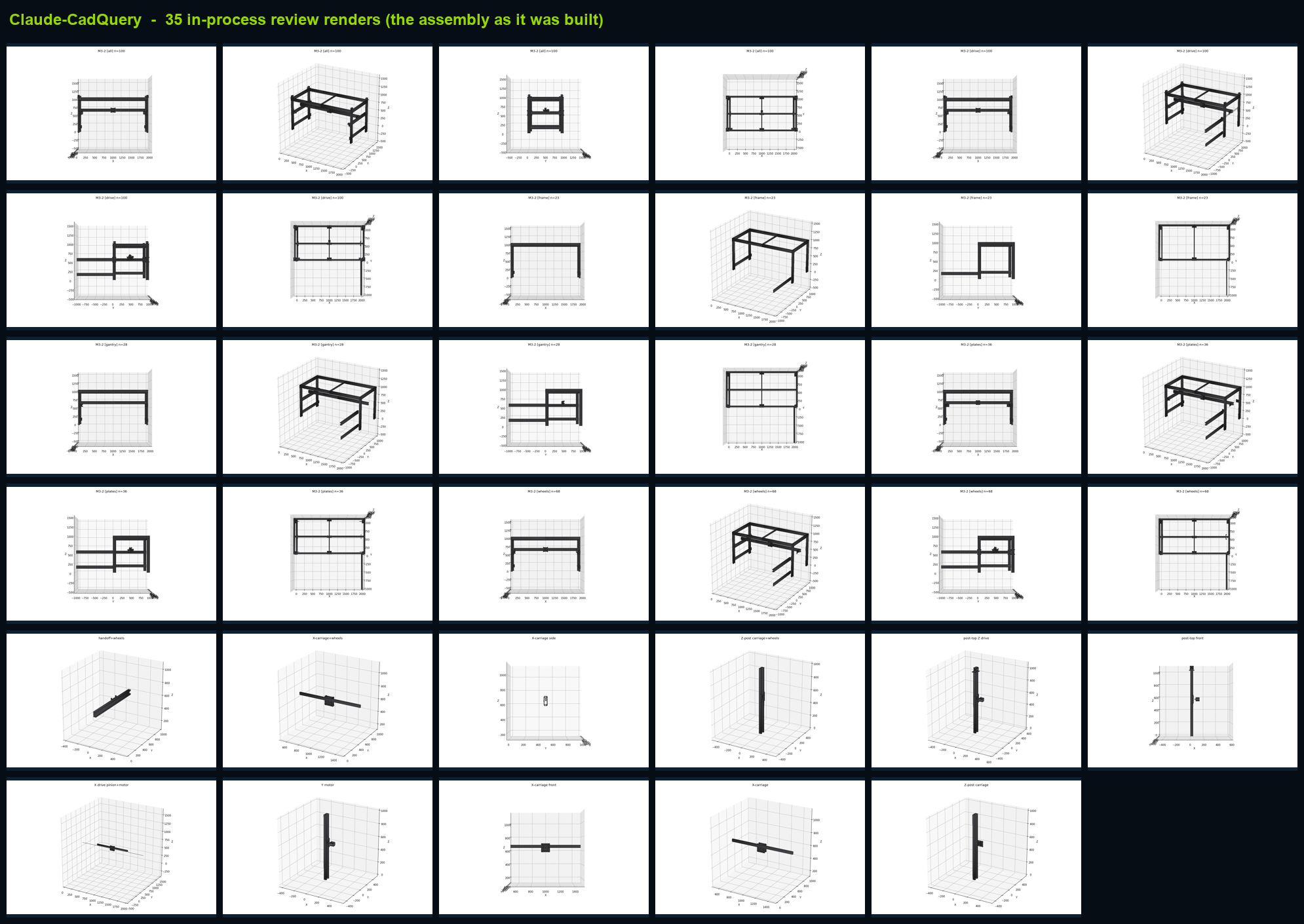
Claude-CadQuery's own in-process renders, the orthographic + isometric checks it generated as it built. This is the human-reviewable output that lets a watcher catch a bad run early and stop it to save tokens.
What we asked, and what we didn't
We gave the goal, not the method. The driver got the target, the pictured assembly plus design constraints, and the kit, but not the build sequence. The original human-guided build specified an inside-out order (X axis → Y → Z-posts) and detailed steps; here we deliberately withheld that and let the AI decide how to reach the pictured result.
So MARB really tests whether a model understands the mechanical system: here a V-slot-and-roller gantry, a basic, well-documented pattern. Placing all 100 parts but self-intersecting, with mis-oriented posts, says a model recognizes the parts but not yet how they go together.
Human-reviewable throughout. Both drivers emitted orthographic + isometric renders as they built, so a person could watch the assembly take shape and abort a bad run early to save tokens. (Fusion didn't persist its in-session views, so we recovered the progression afterward straight from the live model via its MCP, see above.)
One point on a bigger graph, and the spread is instructive. The three frontier runs took 13–49 minutes for one ~100-part assembly. The model that iterated most, reviewing its own renders, re-extracting real hole patterns, scored highest but ran longest; the one-shot run was 4× faster and scored lowest. More careful self-review buys accuracy at the cost of time and tokens. That local-anchor point has since landed — a 30-run, graded study of an 80B open-weight model (studies log) — along with a four-setting reasoning-effort sweep and the token ledger.
Why it matters, in plain English
Checking a design for mistakes is one of the most common, and costly, jobs in engineering. The longer a mistake hides, the more it costs. A widely-used rule of thumb, the 1-10-100 rule: a mistake caught while designing costs about $1 to fix; caught while building, about $10; caught after it ships, $100 or more.
Today that checking is mostly done by hand, an engineer rotating a model on screen, hunting for parts that overlap or don't line up. It's slow, easy to miss things, and it doesn't scale. The hours and the escaped mistakes are pure lost value.
Why now, and not a year ago? Two things just arrived at the same time: AI that can actually drive CAD and assemble parts, and an automated checker (CADCLAW) that can prove an assembly is right, instantly, the same way every time. Put them together and you can both build and verify by machine. MARB is the scoreboard that keeps it honest.
For engineers
A pytest-style, tool-independent check that an assembly is buildable, on every change, not just at sign-off.
For programs
Automated, auditable readiness evidence that plugs into the TRL/MRL/IRL gate reviews you already run.
What makes it different
MARB is not "a CAD checker." Specifics separate it from CAD-vendor tooling and from prior benchmarks:
- Grades the shipped STEP, not a vendor's feature tree. Fusion, SolidWorks, and an AI agent are scored the same way, the only fair cross-tool yardstick.
- Scores the whole machine, not part pairs. System-level integrity across every interface at once, where joint/mate datasets stop at two parts.
- Speaks readiness (TRL/MRL/IRL), not a private number. A score drops straight into the gate reviews programs already run.
- Traces to a real, built machine. The reference target is a physical prototype that exists in metal, not only pixels.
- Audits its own claims. CADCLAW ships honesty tooling and refuses to assert a head-to-head it hasn't run.
Papers & data, all of it open
Every result on this site traces to a public artifact. The benchmark repo holds the scoring spec, the graders, the blind kits, the grades, and the full run registry with per-run provenance (model, tool, timing, tokens, attempts).
| Artifact | What it is | Where |
|---|---|---|
| The Angry Millimeter | Recap article: findings to date + the token ledger | marb.cadclaw.io/recap |
| MARB-A: the Pascal lane | New architecture lane: three models build a house in the open-source Pascal editor; one undocumented units field splits the board | marb.cadclaw.io/pascal |
| Studies log | Every experiment: Fable 5 effort sweep, graded local open-weight anchor, first results | marb.cadclaw.io/studies |
| Scoring spec (v0.9) | The canonical, versioned method behind every grade | MARB/spec |
| Frontier track write-ups | Claude tracks comparison + prompt-framework findings | comparison · findings |
| Local-anchor study | 30 runs, six prompt cohorts, graded — the full write-up | MARB/results |
| Grades & registry | Raw graded metrics + per-run provenance incl. recovered token bills | grades · registry |
| Blind kits & graders | Run your own model against the board (kits, harness, metrics) | MARB repo |
| CADCLAW engine | The open verification engine that grades every run | CADCLAW repo |
| Hugging Face mirror | Benchmark dataset, gated answer key, and the live leaderboard Space | dataset · answer key · leaderboard |
Sponsor a run
Every cell on the board costs real compute, and we publish exactly what: the token ledger in the recap is the price list. Sponsorship buys runs the board is missing — new models, tool pairs, and the repeat seeds that turn single results into error bars. Sponsors are credited on the run's provenance line in the public run registry and on this page.
Frontier run · $100
One scripted-CAD frontier build (a CadQuery cell ran ~$70–90 at list price). Adds one point to the board.
Fusion run · $250
One live-GUI run through the Autodesk Fusion MCP (the costliest cell type to date, ~$174). Tests the interface tax on a new model.
Seed cohort · $500
Five repeat runs of one cell — the error bars that separate a result from a lucky draw.
Model sweep · $1,000+
A new model across effort settings plus the multi-agent harness, fully graded and written up. Logo credit on the study.
Sunnyday Technologies is a for-profit company: sponsorships are not tax-deductible charitable donations. For businesses, run sponsorship is typically an ordinary marketing expense; consult your own tax advisor. Sponsorship never influences grading — the method is open, the grader is automated, and every sponsored run is published win or lose.
Read & review
We are publishing the ladder and the readiness correlation as a candidate standard and inviting the field to measure against it.
Reviewers and collaborators welcome, labs, CAD vendors, and standards bodies especially.