The Angry Millimeter — what tokens cost today for AI-driven CAD assembly
Two weeks ago we asked a simple question: can an AI assemble a real machine? The newest entrant — Anthropic's Claude Fable 5, the first Mythos-class model — now holds four of the eleven cells, including rank 3 with a multi-agent harness and the value corner of the token chart below. Eleven ranked cells and more than thirty graded runs later — frontier hosted models, a brand-new model at four effort settings, local open-weight models a shop could run with no internet, and a vision model that gets to see the goal — we have a board, a set of findings that keep repeating, and a first honest look at the question your CFO will ask before your engineers do: not "can it," but "what does each millimeter of precision cost in tokens?"
The task, in one paragraph
Every run gets the same blind kit: the authored STEP parts of the M3-CRETE concrete-printer frame, four goal renders (a 3/4 overview plus front, top, and side views), and a task brief. No answer key, no build steps, no memory of past work. The model assembles the machine in its CAD tool of choice and exports one STEP file. The CADCLAW grader then scores three things against the answer key: GAP (how far each interface is from its intended gap — about 0 mm where parts bolt, 1–2 mm where they move), ORIENT (the share of asymmetric parts in the correct rotation), and POS (each part's position error after best-fit alignment). Same kit, same grader, every time. Method and scoring spec are open.
The board
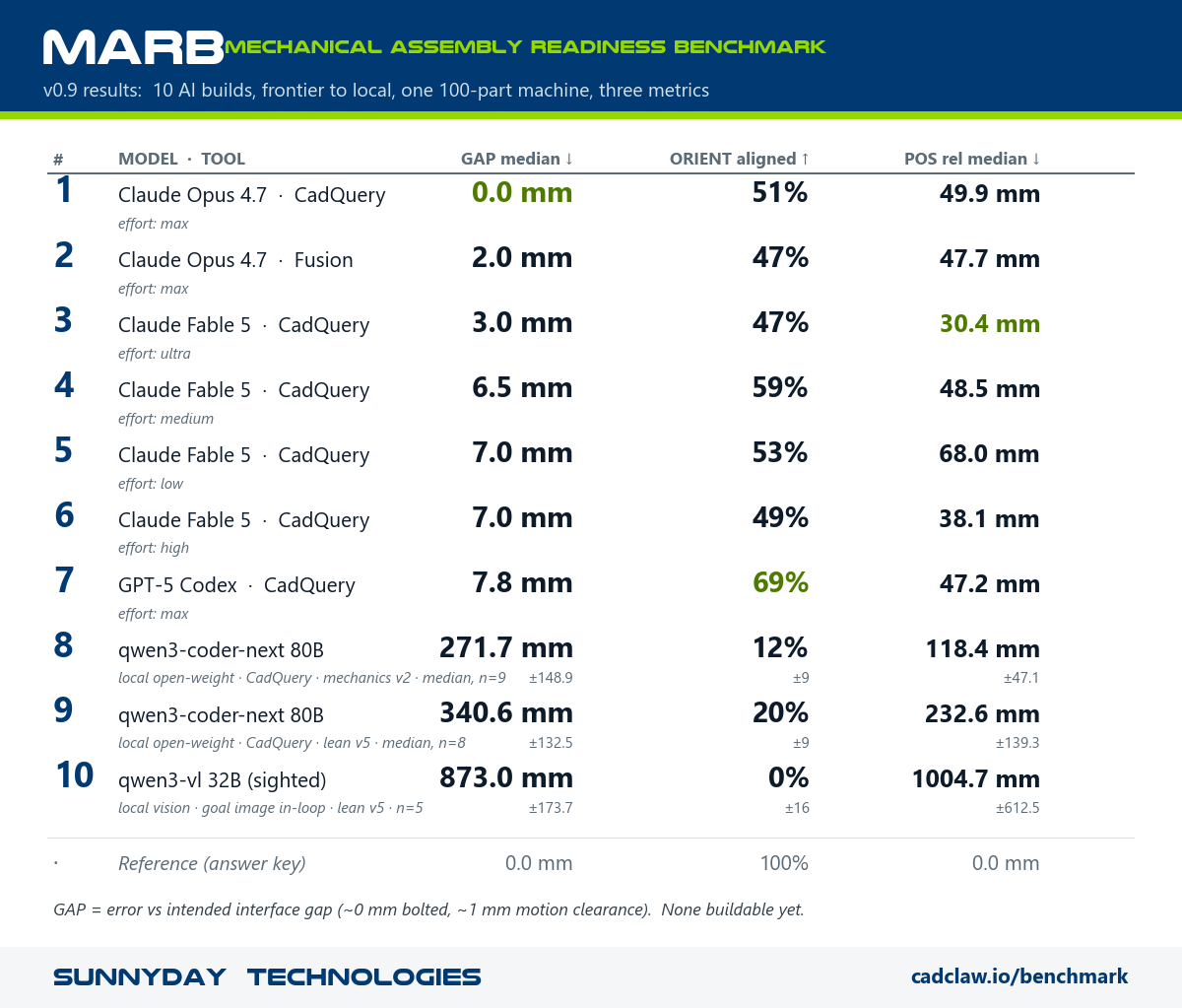
| # | Model · tool | Effort | GAP median | ORIENT | POS rel. | Time |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4.7 · CadQuery | max | 0.0 mm | 51% | 49.9 mm | 49 min |
| 2 | Claude Opus 4.7 · Fusion | max | 2.0 mm | 47% | 47.7 mm | 34 min |
| 3 | Claude Fable 5 · CadQuery | ultra (multi-agent) | 3.0 mm | 47% | 30.4 mm | 83 min |
| 4 | Claude Opus 4.8 · Fusion | kit v1.3 (hint) | 5.7 mm | 39% | 52.5 mm | 41 min |
| 5 | Claude Fable 5 · CadQuery | medium | 6.5 mm | 59% | 48.5 mm | 39 min |
| 6 | Claude Fable 5 · CadQuery | low | 7.0 mm | 53% | 68.0 mm | 38 min |
| 7 | Claude Fable 5 · CadQuery | high | 7.0 mm | 49% | 38.1 mm | 45 min |
| 8 | GPT-5 Codex · CadQuery | max | 7.8 mm | 69% | 47.2 mm | 13 min |
| 9 | Local qwen3-coder-next 80B (n=9) | mechanics v2 | 272 ± 149 mm | 12% | 118 ± 47 mm | ~4.5 min/run |
| 10 | Local qwen3-coder-next 80B (n=8) | lean v5 | 341 ± 133 mm | 20% | 233 ± 139 mm | ~4.5 min/run |
| 11 | Sighted qwen3-vl 32B (n=5) | lean v5 + goal image | 873 ± 174 mm | 0% | 1005 ± 613 mm | ~30 min/run |
| · | Reference (answer key) | 0.0 mm | 100% | 0.0 mm |
None of these machines is buildable yet. That is the standard, and it is the right one: the target is a frame you could bolt together as exported. With that said, the board is no longer a single data point — it is a curve, and the curve has lessons.
Findings to date
1. Placing parts is solved. Locating them is not. Every frontier run placed roughly all 100 parts at roughly the right scale. The grader's job starts after that, and the spread is wide: a part can be present, correctly chosen, and still sit 5 mm — or 400 mm — from where the machine needs it. This is the gap between a render that looks right and a machine that bolts together, and it is exactly the gap human review at screen scale cannot see.
2. Iteration buys precision; one-shot buys speed. Pick one. Claude Opus 4.7 on CadQuery re-extracted real hole patterns across nine attempts and hit the answer key's interface gaps at 0.0 mm median — in 49 minutes. GPT-5 Codex one-shotted the build in 13 minutes, loosest gaps on the frontier (7.8 mm) but the most parts in the correct rotation (69%). Neither is wrong. They are different products.
3. Effort knobs are not monotonic. Claude Fable 5 at low, medium, and high reasoning effort produced a scramble, not a staircase: medium beat both neighbors on GAP (6.5 mm) and orientation (59%); high bought better relative position and nothing else. If you assumed the expensive setting buys a better machine, the grader disagrees.
4. Structured verification beats raw effort. The Fable 5 ultra run kept the model and changed the harness: probe every kit part first, build, then run a four-agent adversarial audit (collision booleans, per-constraint arithmetic, visual comparison against the reference, BOM counts), then fix what the audit found. It caught a motor shaft 4.9 mm short of its pinion, belts cutting 3.4 mm into an idler, and a pulley installed hub-backwards — none visible in renders — and finished at 3.0 mm GAP with the best relative position on the board (30.4 mm). Same model that scored 7.0 mm at the "high" setting. The thinking didn't improve; the checking did.
5. The same lesson holds at the bottom of the curve. The local 80B open-weight model went from 1-in-5 to 5-in-5 buildable exports on a two-line fix naming the correct CadQuery export call — and got worse every time we added more guidance, more design objectives, or more turns (one 14-turn run burned 113K tokens in a probe loop and exported nothing). Lean, failure-targeted instructions won. Undirected budget converts to tokens, not to quality, at every scale we've measured.
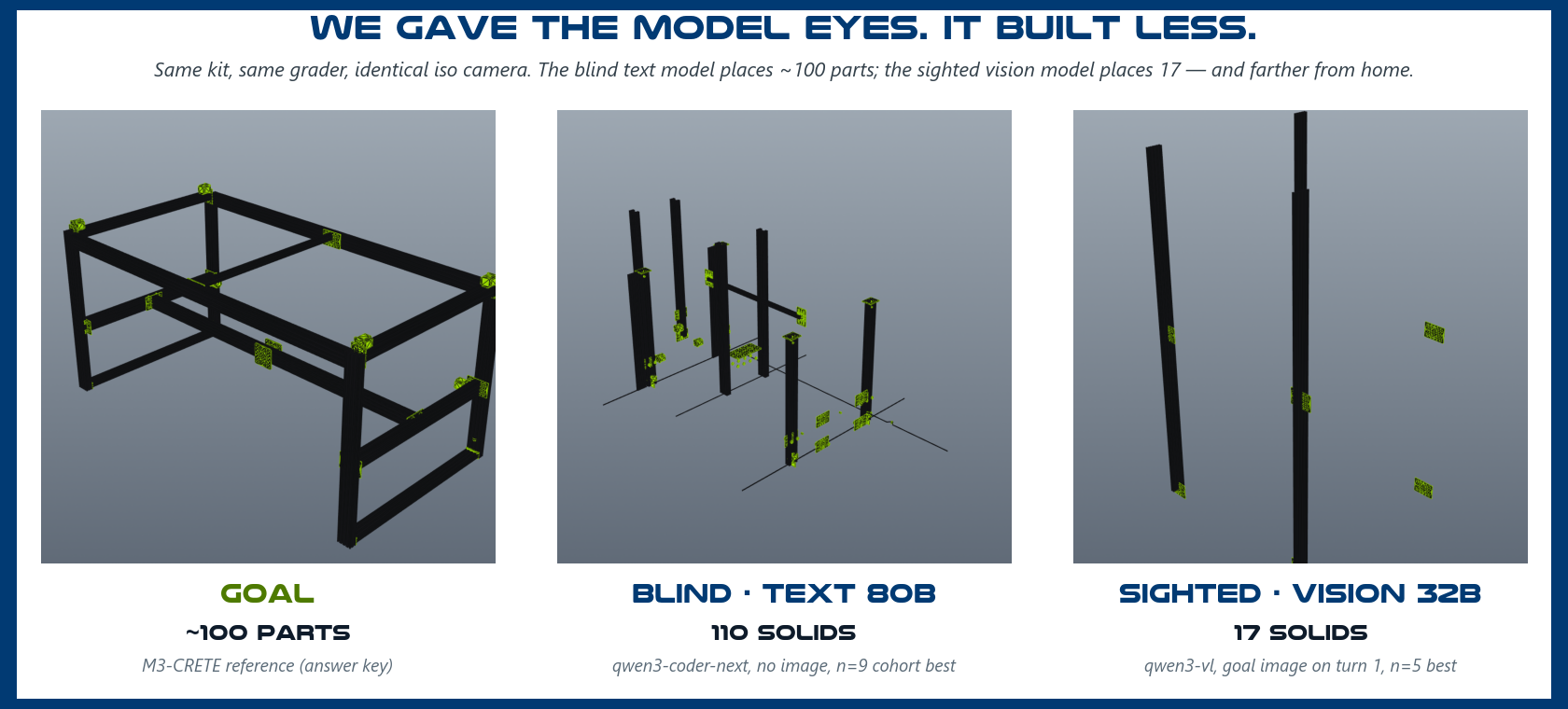
6. Seeing the goal did not help — it hurt. The newest cells hand a local vision model (qwen3-vl 32B) the goal image directly, on turn one. It exports reliably (5/5) and places only 12–17 parts at 873 mm GAP — roughly a sixth of the parts and three times the error of the blind 80B text model. A 12-turn variant (preliminary) sharpens placement but not coverage, and a second vision model (Nemotron 3 Nano Omni) never produced a loadable export in five attempts. At local scale, image tokens crowd out geometry. Details and the honest size-confound caveat are in the sighted study.
7. More seeds shrank the flattering numbers. The local text cohorts were extended from five seeds to ten: "5/5 buildable" became 9/10 and 8/10, and the spreads widened (mechanics v2 GAP is now 272 ± 149 mm). Single-cohort rates flatter; the board now carries the honest error bars.
8. The floor is honest and far away. The local builds place roughly the right parts at roughly the right scale, 100–400 mm off, with ~30% correct rotations and 20–28 pairs of clipping solids: parts grouped, not jointed. That is a 40× GAP distance from the frontier mid-board, now measured rather than guessed — and the curve will show exactly when open-weight models start closing it.
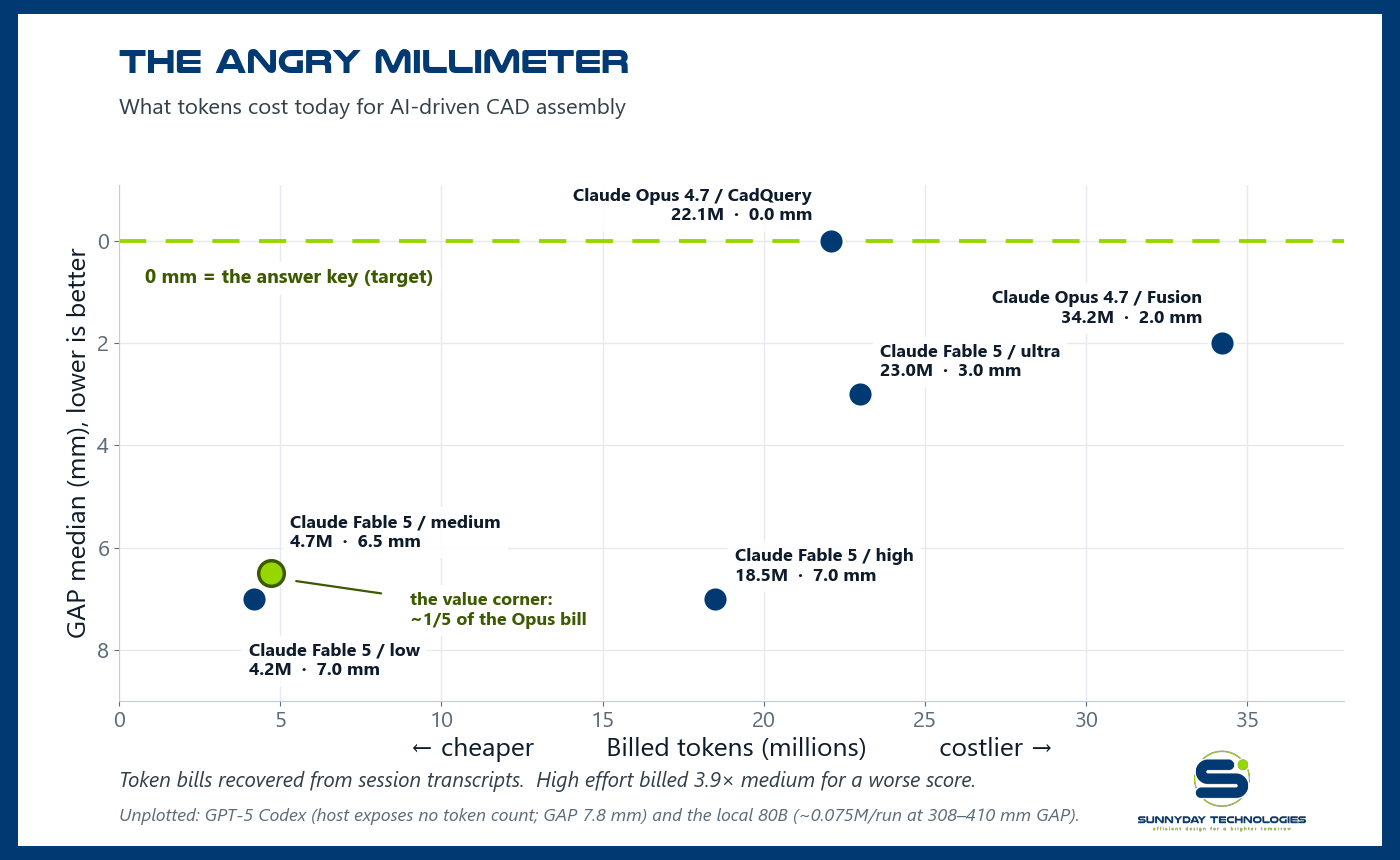
The token ledger: who is making the best use of tokens?
First, the honest part: hosts don't hand you this number. The harness captures token usage natively only for the local runs; for every Claude run we recovered the full bill after the fact by summing the per-message usage blocks in the session transcripts (the recovery script ships in the repo). The Codex CLI exposes nothing, in the session or on disk. Here is the ledger:
| Run | Billed tokens | Output tokens | Capture | Attempts | GAP result |
|---|---|---|---|---|---|
| Opus 4.7 · CadQuery | 22.1M | 321K | recovered from transcript | 9 | 0.0 mm |
| Opus 4.7 · Fusion | 34.2M | 1.15M | recovered from transcript | 12 | 2.0 mm |
| Fable 5 · ultra | 23.0M | 614K | recovered from transcript | 8 | 3.0 mm |
| Fable 5 · high | 18.5M | 442K | recovered from transcript | 4 | 7.0 mm |
| Fable 5 · medium | 4.7M | 374K | recovered from transcript | 3 | 6.5 mm |
| Fable 5 · low | 4.2M | 330K | recovered from transcript | 3 | 7.0 mm |
| GPT-5 Codex | not exposed by host, in-session or on disk | unavailable | 1 | 7.8 mm | |
| Local 80B (per run) | 35–139K total (median ~75K) | full, native | 1 | 272–341 mm | |
| Sighted 32B (per run) | 67–122K total | full, native | 1 | 873 mm | |
With the full ledger, four things stand out.
The most expensive run was not the best run. Opus on Fusion billed 34.2 million tokens — 55% more than Opus on CadQuery — and scored worse on all three metrics. The difference wasn't intelligence; it was the interface. Driving a live GUI application through its MCP connection burns tokens on round-trips that writing a build script does not. Tool choice is a token-efficiency decision before it is a capability decision.
The value play on the board is Fable 5 at medium effort. 4.7 million billed tokens — about a fifth of Opus CadQuery's bill — bought 6.5 mm GAP and the second-best orientation score (59%). On output tokens, the expensive kind, medium spent 374K to Opus CadQuery's 321K: nearly the same actual writing, vastly less re-reading. If you are buying assembly attempts by the token, this is the current price-performance corner.
The "high" setting is the cautionary tale, now with a price tag. High effort billed 18.5 million tokens — 3.9× medium — and scored worse on GAP and orientation. The non-monotonic effort curve isn't just a quality observation; it is paying quadruple for a worse machine. Undirected thinking budget converts to cache reads, not to precision.
Structured verification buys precision at a fair price. The ultra run's full bill came to 23.0 million tokens — within 4% of Opus CadQuery's 22.1M — including the ~497K spent by the adversarial audit subagents. Same spend, different shape: Opus bought 0.0 mm GAP with nine sequential self-review attempts; ultra bought 3.0 mm GAP plus the board-best relative position with one build and a structured audit. Two routes to precision at the same bill — and both confirm the same law: the tokens that move the grade are the checking tokens.
So, who is making the best use of tokens? Fable 5 at medium effort on raw value; the verification-heavy harnesses on absolute precision. GPT-5 Codex remains the unmeasured dark horse — one attempt, 13 minutes, best orientation on the board, no token count to judge it by. That capture gap is itself a finding: as of this recap, MARB run logs require a token_usage block, transcript recovery is a published tool, and "unavailable" is recorded as the result it is.
Honest limits
- Every frontier cell is a single run. The local cells are n = 5. Treat single-run deltas as directional; we add seeds before we call trends.
- Token capture is missing for half the board, which is why this article bounds claims instead of ranking by a number we don't have.
- The grader scores per-part pose and interface gaps. It does not yet score connectivity — whether parts join into one rigid structure. That gate (L1) is the next grader level, and the local study is exactly why: it is possible to score parts near their homes while building nothing a wrench could touch.
- None of the eleven builds is buildable as exported. The benchmark exists to measure the distance, not to declare victory early.
What's next
Seeds on the frontier cells, the L1 connectivity gate, vision-enabled cells (the same task with the goal image in-loop for sighted local models), and token capture as a first-class requirement. The board updates as runs land: the benchmark page has the current ranking, the studies log has every experiment with its method, and the scaffold — prompt, scoring spec, grader — is open for anyone who wants to put their own model on the board.
Method, grades, run registry with full provenance, and the CADCLAW engine: GitHub. Reviewers welcome — [email protected].